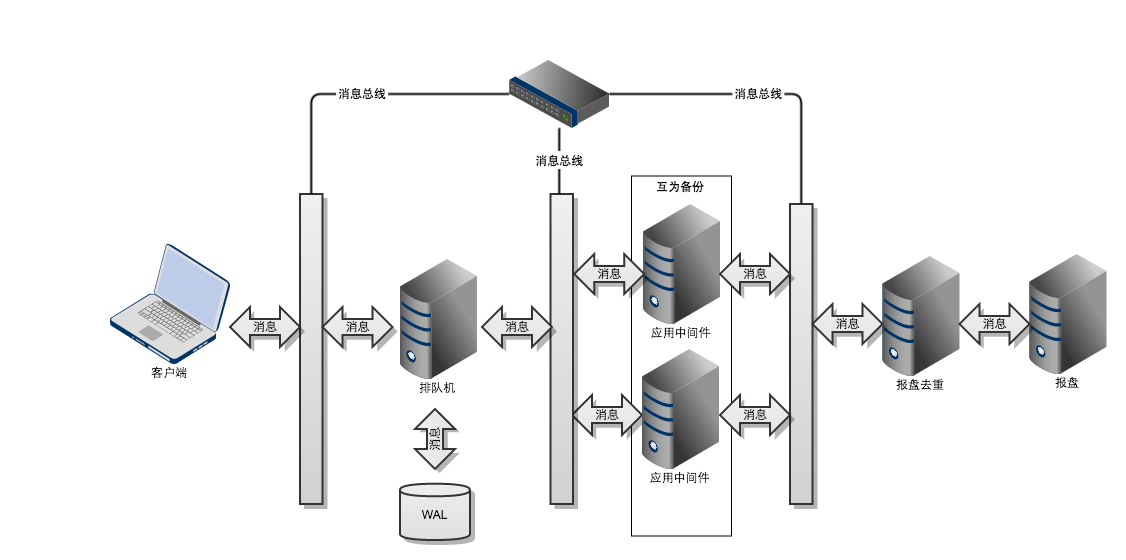
概述
数据的可靠传输是任何通信基础设施必须要考虑的问题。由于数据通过网络传播要经过多种设备和中间件,所以有可能会乱序,或者丢失部分数据。一般做法是发送端将消息排序后发送,接收端按照顺序接收消息。如果发生乱序,接收端负责组装,如果发生消息丢失,发送端重发数据。
发送端不可以任意的往网络上发送数据,必须考虑网络的带宽,以及接收端的消费能力。为了维持发送端和接收端之间的稳定连接,接收端需要发送确认消息给发送端,有两种确认消息的方式,ACK和NAK(Negative ACK),TCP采用的是ACK,而多播则采用NAK。
基于ACK的可靠传输
我们先以TCP为实例看一下基于ACK的可靠传输机制,下图是图例

初始状态,TCP的发送窗口大小为8,下图表示序号为0,1,2的数据已成功发送并得到接收端的确认,这些数据不用重新发送,可以从缓存中删除。而序号3,4已经发送,但还未收到确认,仍然留在缓存中。序号5至10可以发送,应用还未发送。序号11以上超出发送窗口(3-10)的范围,不可发送。

如果超过一定时间仍然没有收到3和4的确认,那么滑动窗口向左回退,于是应用重传3,4序号的数据,这便是回退n协议。回退N协议规定即使接收端收到了序列为4的数据,如果没有收到3,则只能将确认序号设为2。

更高效的做法,接收端收到4立刻,确认4,而发送端在重传时只需重传序号3,这便是选择重传协议(又叫SACK)

当发送端收到序号为3的确认之后,窗口向又滑动,序号3可以从缓存中删除,序号11可以发送。

TCP之所以采用ACK的方式确认,主要目的是为了拥塞控制,因为Internet跨度大,网络传输各种因素影响较大,等到接收端的ACK之后再发送后续的数据,可以保证发送端不至于发送太多的数据占满带宽或者超出接收端的处理能力。TCP的慢启动和拥塞控制算法也都是基于ACK的,这样做是为了维护一个稳定可靠的互联网,否则很有可能有限的出口带宽被少数几台机器撑满。但是在高速网络上,TCP不够高效的问题就显露出来:
- 高速网络上,丢包概率小,太多的ACK反而造成负担,而且发送端要等待ACK回来才能继续发送,会导致一定的时延。
- 更主要的问题,多播的情况,一个滑动窗口满足不了多个接收端可靠传输的需要。
基于NAK的可靠传输协议
多播的解决方案是采用更激进的NAK协议,以下也以一个实际的例子解释:
如下图所示,序号0-4是已经发送的数据,而5以后都是可发送数据,窗口没有右边界,发送过的数据也会保留较长时间(甚至落地存储,即Event Sourcing)

如果发生丢包,接收端会在超时之后向发送端发送一条序号为3的NAK消息,于是序号3,4重新打开,发送端重发3,4以及以后的数据,这里还是回退N协议。

如果有多个接收端同时发送了多条NAK消息,那么有几种处理方式:
- 取最小序号的NAK消息,这还是回退N协议
- 为每一个发送NAK消息的接收端建立一条单独的窗口,这就是分组回退协议
- 接收端的NAK消息指定哪些消息没收到,而不仅仅是一个序号,这样每一个窗口可以做有选择的重传,此即分组选择重传协议
NAK协议更加激进的发送数据,只要没有收到NAK就可以发送数据,因而吞吐和时延比ACK协议会好,在高速网络上,NAK一般会比较少,所以不用担心分组回退会引起吞吐下降。即使最坏的情况,由于采用了多播,也不会比TCP多条连接的情况差。
在出现网络波动的情况下,或者有个别慢接收端的情况下,TCP拥有慢启动和拥塞控制算法,仍然可以保证可靠传输不丢数据。NAK协议也需要有一套相应的拥塞控制和启动算法(未完待续)。